 Optimising the ThreeHump problem.
Optimising the ThreeHump problem.Abstract
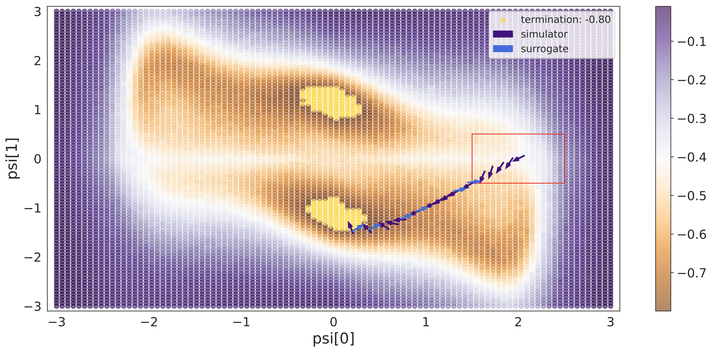
In recent years, inverse problems for black-box simulators have enjoyed increased focus of the machine learning community due to their prevalence in science and engineering domains. Such simulators describe a forward process f (\psi, x) \rightarrow y. Here the intent is to optimise simulator parameters \psi to minimise some observation loss on y, under some input distribution on x. Optimisation of such objectives is often challenging, since it is not trivial to estimate simulator gradients accurately. In settings where multiple related inverse problems need to be solved simultaneously, from-scratch/ab-initio optimisation of each may be infeasible if the forward model is expensive to evaluate. In this paper, we propose a novel method for solving such families of inverse problems with reinforcement learning. We train a policy to guide the optimisation by selecting between gradients estimated numerically from the simulator and gradients estimated from a pre-trained surrogate model. After training the surrogate and the policy, downstream inverse problem optimisations require 10%-70% fewer simulator evaluations. Moreover, the policy does successful optimisations on functions where using just simulator gradient estimates fails.
Tim Bakker
PhD researcher in Machine Learning
My research interests include AI alignment, active learning/sensing, reinforcement learning, ML for simulations, and everything Bayesian.